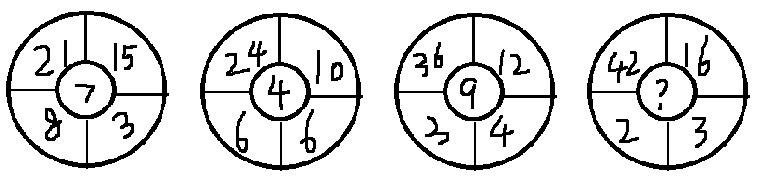导航
行测
言语理解
判断推理
数量关系
资料分析
公基常识
申论
公安
时政
其他
搜索
时政
每日日报
2025/4/20
1218阅读
其他
百度网盘画质插件
2025/6/10
4阅读
其他
百度网盘Win/Mac电脑端倍速教程
2025/6/10
1407阅读
默认分类
百度倍速华为手机常见问题
2025/6/10
1228阅读
2025/4/19
数量关系
几何问题
几何问题 几何问题⭐⭐ 一、公式定义 1、周长定义:平面图形的边界长度,简单来说就是围绕一个平面图形的一圈长度。对于圆形,则指圆的边界,称为圆周长或圆周。 2、面积定义:面积是对一个平面的表面多少的测量...
507阅读
0评论
2025/4/19
数量关系
经济利润问题
经济利润问题 一、公式型问题 基本公式 1、 总价=单价×数量 2、 利润=售价-成本 3、 利润率=利润成本利润成本=售价成本成本售价−成本成本=售价成本售价成本-1 4、 总利润=...
578阅读
0评论
2025/4/19
数量关系
行程问题
1、考察频率:考得挺多,有简单题也有很难的题,中等难度偏多。行程问题难点在于行程问题需要一句一句理解,并根据题目给出的信息,抓住问题,画图呈现出来。 2、掌握程度:能够掌握中等难度的题型。考场上能辨别难题,遇到很难就可以放弃不要浪费时间。 3、解题思路:...
522阅读
0评论
2025/4/19
数量关系
牛吃草问题
牛吃草问题 牛吃草问题又称为消长问题,是 17 世纪英国伟大的科学家牛顿提出来的。典型牛吃草问题的条件是假设草的生长速度固定不变,不同头数的牛吃光同一片草地所需的天数各不相同,求若干头牛吃这片草地可以吃多少天。由于吃的天数不同,草又是天天在生长的,所...
490阅读
0评论
2025/4/19
数量关系
工程问题
工程问题 一、核心公式 1、工作量 = 工作效率 × 工作时间 2、工作效率 = 工作量 ÷ 工作时间3、工作时间 = 工作量 ÷ 工作效率 二、解题思路 1、条件只给岀完工时间的具体值:通过给总量赋值,一般...
557阅读
0评论
2025/4/19
数量关系
方程思想
方程思想 数学运算的大部分题型,都可以使用方程法思想来解答。其中,对于一些典型题型,如“盈亏问题”、“鸡兔同笼问题”、和差倍比问题“等等,使用方程法思想解题才是最快的。 ...
506阅读
0评论
2025/4/19
数量关系
十字交叉
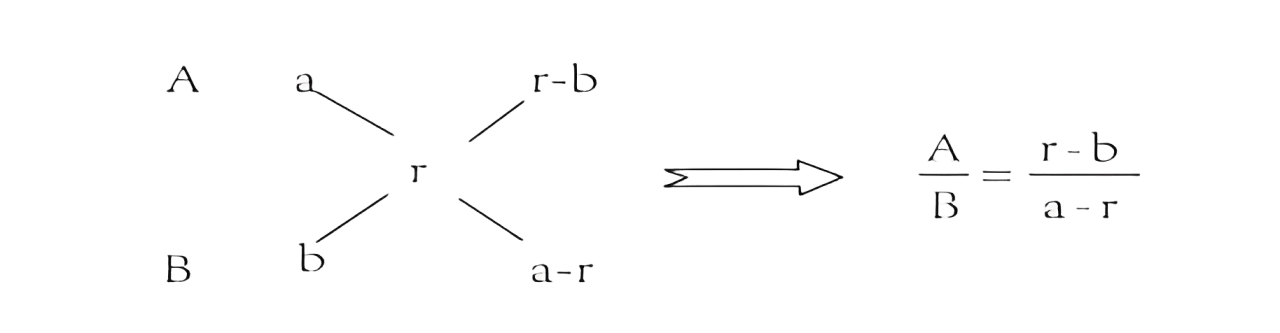
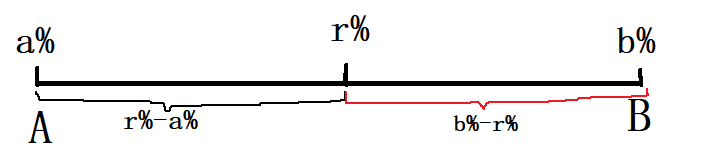
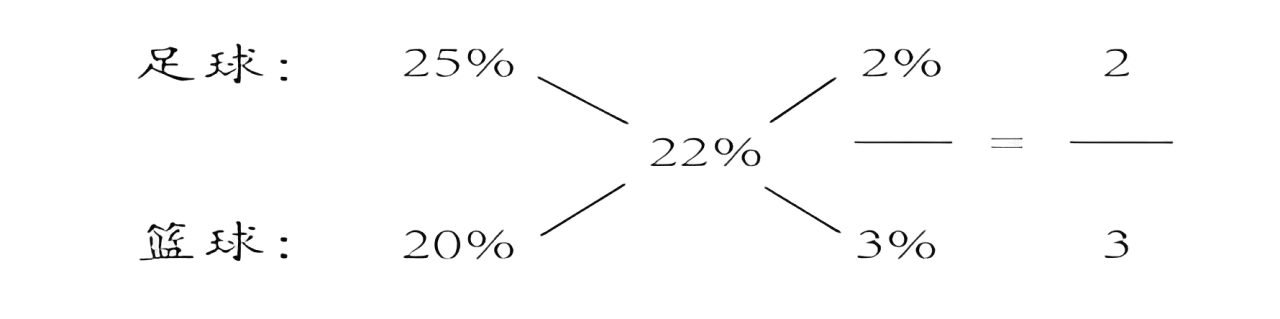
十字交叉 十字交叉法实际上是一种方程计算过程中的简化形式。主要用来解决两者之间的比例关系问题,在行测中资料分析以及数量关系都会涉及到。 一、十字交叉法 1、方法来源:十字交叉法最先是从溶液混合问题(两个部分混合成一个整体)衍生而来的。公式:浓度(%)=...
463阅读
0评论
2025/4/19
数量关系
逆向推理
逆向推理 一、什么是逆向推理 如果一道题从正面求解所涉及的情况比较复杂,计算起来比较麻烦的话,那么我们就可以从其相对的一面进行考虑,或者以最终状态作为突破口进行反推计算,以此来简化问题的一种解题思维。 ...
552阅读
0评论
2025/4/19
数量关系
赋值思想
赋值思想 一、定义 在解数量关系题目时,一步一步地寻找条件列式计算,是一种常用的方法。然而,对于有些题目,若能合理地对某些元素赋值,特别是赋予方便计算的特殊值,往往能使复杂问题简单化。 &...
519阅读
0评论
2025/4/19
数量关系
奇偶特性
奇偶特性 一、在乘法中 若因子中存在偶数,则结果为偶数;无偶数则结果为奇数 ①奇数 × 奇数 = 奇数 ②偶数 × 偶数 = 偶数 ③奇数 × 偶数 = 偶数 二、在加减法中 两个因子奇偶性相同,则...
512阅读
0评论
2025/4/19
数量关系
余数特性
余数特性 一、基本公式 余数基本关系式∶被除数÷除数=商……余数(0≤余数<除数) 余数基本恒等式∶被除数=除数×商+余数 二、同余定理 同余问题定义在【带入排除】章节已详细讲解,点...
492阅读
0评论
2025/4/19
数量关系
倍数特性
倍数特性 一、整除型 定义:将除数a分解成两个互质的整数b和c,若同时被b和c整除,则可以被a整除 整除的传递性:被b整除,b 被c整除,则a被c整除。 整除的可加减性:α被c整除,b 被c整除,则 a±b 都可以被c整除 口...
754阅读
0评论
2025/4/19
数量关系
代入排除思想
一、优先使用代入排除题型 1.涉及年龄、多位数、余数、不定方程等固定题型; 2.看完题干不知道如何入手,没有思路也可以尝试代入排除法; 3.如果通过分析或者其他方法的计算,依然剩下...
537阅读
0评论
2025/4/19
数量关系
特殊数列
特殊数列是考查频率较低。偶尔会出现,考查形式多变,规律灵活,难以归类。近年来特殊数列多考查题干数字位数较多的题型,我们可对此类题型重点掌握。 一、机械拆分 1、题型特征:数列比较奇怪,比如有小数点、根号、位数多、首项数字大等等,且一般作...
473阅读
0评论
2025/4/19
数量关系
递推数列
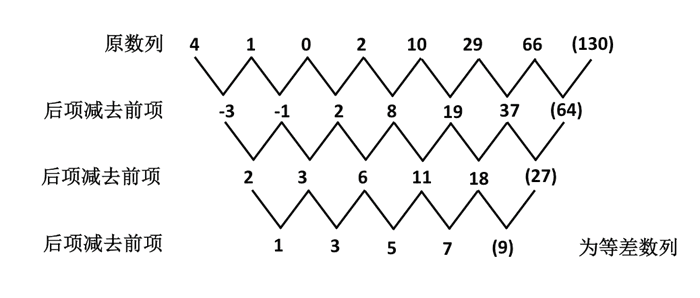
递推数列是数字推理中难度较高的一类题型,虽然题量不大,但是考查形式变化多样,属于数字推理题目中的难点。 一、基本特征 1、数列中前面的项通过某种特定的运算,得出下一项从而形成规律,通常将数列中的两项进行运算得到第三项。常见的运算方式有和、差...
471阅读
0评论
2025/4/19
数量关系
多级数列
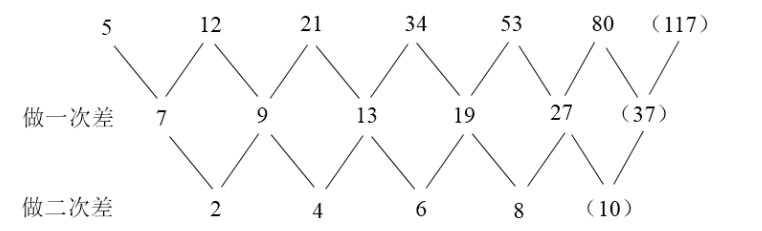
多级数列是数字推理中考查频率最高的题型,每年必考,但难度不高,考查方式相对变化不大,各位需重点掌握。 一、题型特征 没有明显特征的数列 二、解题技巧 1、第一步:优先考虑两两做差或两两做和,不行再考虑除法;如果数字之间成“倍数关...
467阅读
0评论
2025/4/19
数量关系
图形数列
而图形题相较于分数数列、递推数列、多级数列等常见纯数字数列来说,在没有掌握一些常见技巧的前提下确实无从下手。目前在江苏、浙江、广东、吉林等有可能考查到这一考点,还有部分事业单位的考试。 一、题型特征 题干出现图形,常见的有圆圈题...
497阅读
0评论
2025/4/19
数量关系
幂次数列
幂次数列 幂次数列在数字推理中难度较高,大概每年1道,考查形式多样,属于数字推理题目中的难点。 一、题型特征 1、数列呈递增趋势且变化幅度较大 2、数字本身是幂次数 3、数字在幂数附近:需要通过幂次数再做一些简单计算才能得到...
553阅读
0评论
2025/4/19
数量关系
作商数列
作商数列 作商数列在数字推理中比较常见,几乎每年都有涉及,一般最多出现1道,并且难度不高,需重点掌握。一、题型特征 相邻两项有明显的倍数关系。二、解题技巧 三、随笔练习 例1:(2018新疆)3、6、18、72、360、()A.216...
431阅读
0评论
2025/4/19
数量关系
分数数列
分数数列属于高频考点,近年来几乎所有考查数字推理的省市,如江苏、广东等都会涉及。此类题型易于识别,分子、分母规律变形不多,我们只要掌握方法,就可在考场上快速地解答此类题型,建议重点掌握。 一、题型特征 题干中含有多个分数,一般...
522阅读
0评论
«
1
...
5
6
7
8
9
10
11
»