导航
技术教程
实用工具
值得一看
福利分享
心灵鸡汤
赚钱项目
搜索
赚钱项目
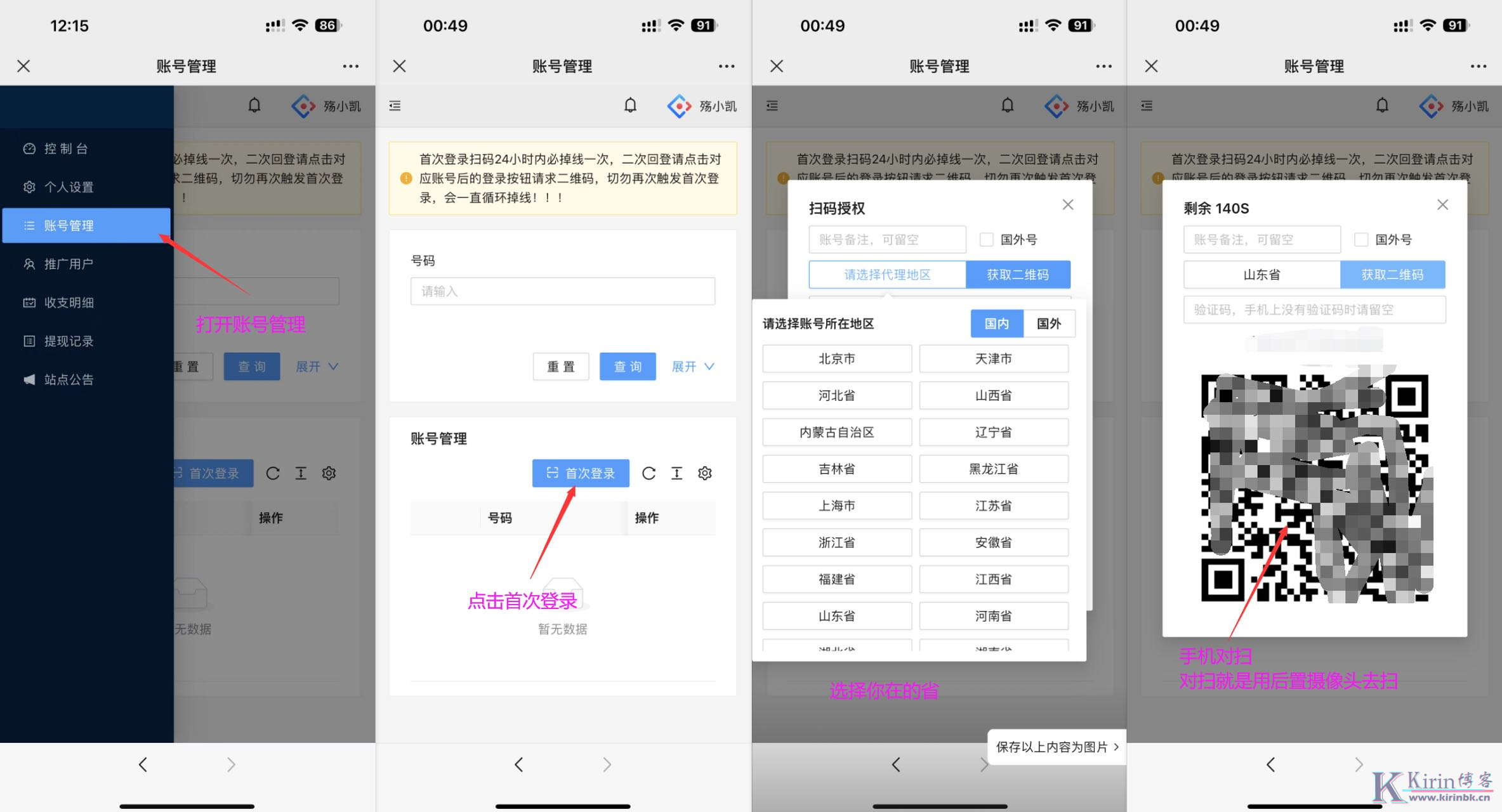
172号卡分销系统推荐人手机号
推荐人手机号
2024/7/25
1500阅读
赚钱项目
新手第一课,教你如何推出第一张卡
2024/7/25
1355阅读
赚钱项目
微信视频号托管平台(每天15元现金)
2024/4/10
2084阅读
技术教程
如何绕过网站复制限制?7种实用技巧与合法注意事项
2025/2/26
87阅读
2024/4/5
技术教程
【MySQL】数据库排查慢查询、死锁进程排查、预防以及解决方法
MySQL数据库排查慢查询、死锁进程及解决方法 一、排查慢查询 1.1检查慢查询日志是否开启 1.1.1使用命令检查是否开启慢查询日志: SHOW VARIABLES LIKE 'slow_query_log'; 如果是 Value 为 of...
671阅读
0评论
2024/4/5
技术教程
前端开发:Vue3提示警告Failed to resolve component:XXX If this is a native custom element… 的解决方法
前言 在前端开发中使用Vue的开发者都知道,Vue目前已经以Vue3.0为基础版本了,也就是说Vue3.0已经成为主流版本了。还在只用Vue2.0开发没有使用Vue3.0的开发者要注意了,要抓紧时间熟悉和了解Vue3以上的相关语法和知识点了,迫在眉急。本篇博文...
552阅读
0评论
2024/4/4
技术教程
Excel如何将FILTER函数筛选结果多余的错误值去掉?
Excel如何将FILTER函数筛选结果多余的错误值去掉? 很多同学常用WPS处理表格数据,再用WPS表格提取数据的时候有一个很好用的函数Filter函数,它可以自动提取符合条件的数据,操作起来方便快捷。 但是如果我们所选择的区域太大,可能筛选结果会出现错误值...
564阅读
0评论
2024/4/4
技术教程
Excel中利用Filter函数进行多条件筛选数据的2种方法
Excel中如何利用Filter函数进行多条件筛选数据? 很多同学常用WPS处理表格数据,再用WPS表格提取数据的时候有一个很好用的函数Filter函数,它可以自动提取符合条件的数据,操作起来方便快捷。但是在Excel的Filter函数介绍中只介绍了单条件筛...
452阅读
0评论
2024/4/4
实用工具
CloudDrive官网/CloudDrive下载地址 云盘本地挂载软件
CloudDrive是什么?CloudDrive是一个强大的多云盘管理工具,为用户提供包含云盘本地挂载的一站式的多云盘解决方案。 1、CloudDrive是一个全方位的云存储管理平台,旨在无缝集成多个云存储服务,将它们统一整合到一个界面中。 2、使用Clou...
708阅读
0评论
2024/4/4
值得一看
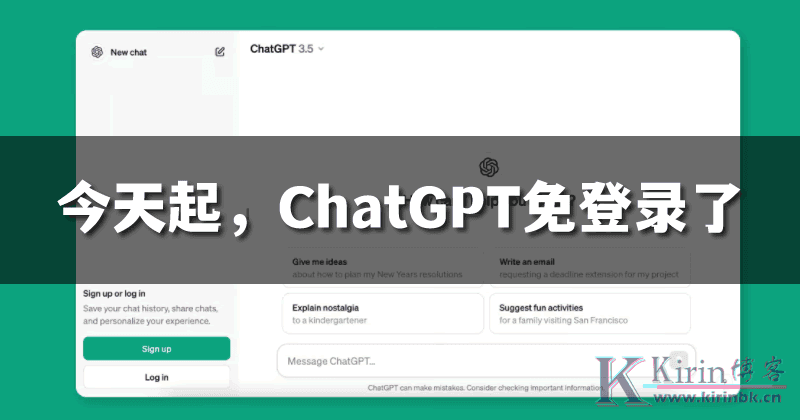
今天起,ChatGPT无需注册就能用了!
OpenAI宣布:从今天起,ChatGPT打开即用,无需再注册帐号和登录了!不过,免登录无法享受一些高级功能,比如分享聊天记录、自定义指令等等。 访问地址是:https://openai.com/ (目前国内用不了) 松松刚测试了一下:使用ChatGP...
403阅读
0评论
2024/4/4
福利分享
某博不好意思晒在好友圈的照片
点击围观
533阅读
0评论
2024/4/4
福利分享
某博小反差[照相机]
点击围观
497阅读
0评论
2024/4/4
值得一看
4月4日,星期四简报,60秒知晓天下事
2024年4月4日,星期四,农历二月廿六,每天60秒知天下 1、台湾花莲县海域发生7.3级地震:已致9死934伤,48栋民宅受损,余震逾200起,气象部门称:未来三天可能还有7级地震; 2、江西风雹灾害:已致7人死亡,9.3万人受灾,直接经济损失1.5亿元;...
409阅读
0评论
2024/4/3
值得一看
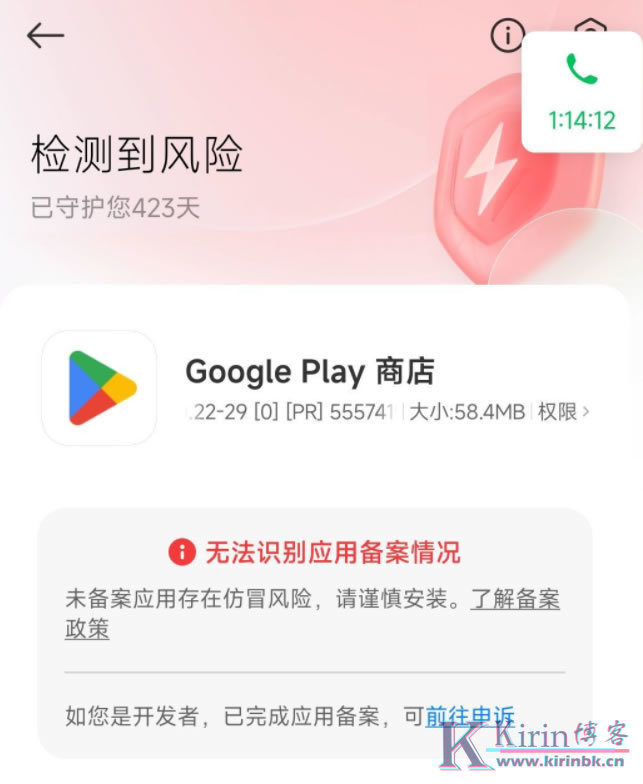
4月1日起,未备案App小程序将下架
从2024年4月1日起,工信部要求所有的APP、小程序都要备案,否则下架、关停、限制更新。这是去年8月份出的新规,没想到十个月这么快就过去了。 现在广东省已备案APP、小程序全国占比分别为22.15%、16.86%。一个广东占比全国近五分之一的份额,还是很...
442阅读
0评论
2024/4/3
技术教程
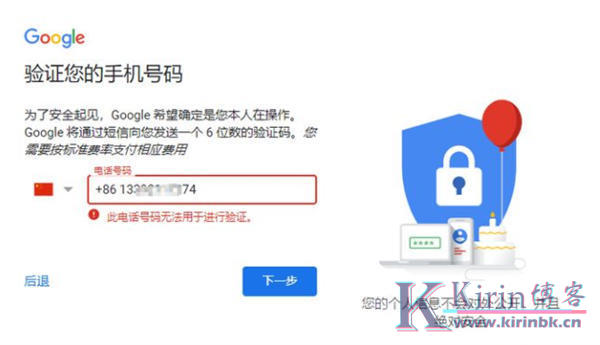
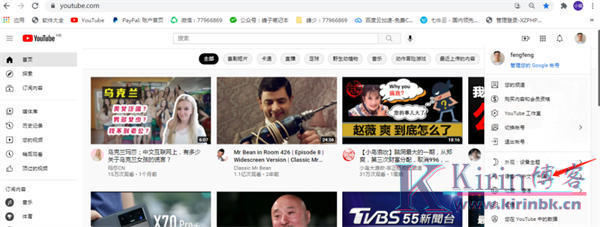
油管YouTube最全教程:从注册到收款
第一步、注册账号 对于纯新手而言,注册账号包括2个流程:一个是注册谷歌账号,一个是创建YouTube频道。 1.注册Gmail邮箱 几年前只要能科学上网,注册Gmail是没什么难度的,但近几年注册很容易失败,最常见的问题就是中国大陆的手机号无法接收验证码。 ...
707阅读
0评论
2024/4/2
技术教程
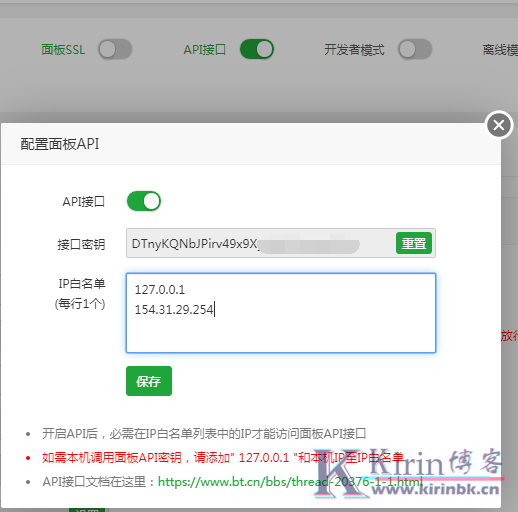
宝塔Linux面板一键迁移网站-Windows面板快速迁移网站
宝塔Linux/Windows面板如何一键迁移网站?相信做网站的站长朋友都会面临着网站搬家的时候,可能原因是网站的服务器不稳定,或者网站发展起来后需要更好的服务器,所以就需要进行网站的搬家了。如果两台服务器都安装有宝塔面板的话,可以在旧服务器的面板上安装&ld...
440阅读
0评论
2024/3/31
值得一看
“客户就是猎物” 今年315之后,婚恋相亲行业整体塌房了?
今年315都看了吗? 央视官方点名婚恋行业之后,相信作为婚恋行业从业者慌不慌,平台一定会进一步对这个行业的收紧,今天还是再聊一聊相亲行业的现状~ 01 婚恋行业的 “ 丑闻 ” 相信也不是一天两天了,这段时间我和多个婚恋公司的负责人或老...
416阅读
0评论
2024/3/30
实用工具
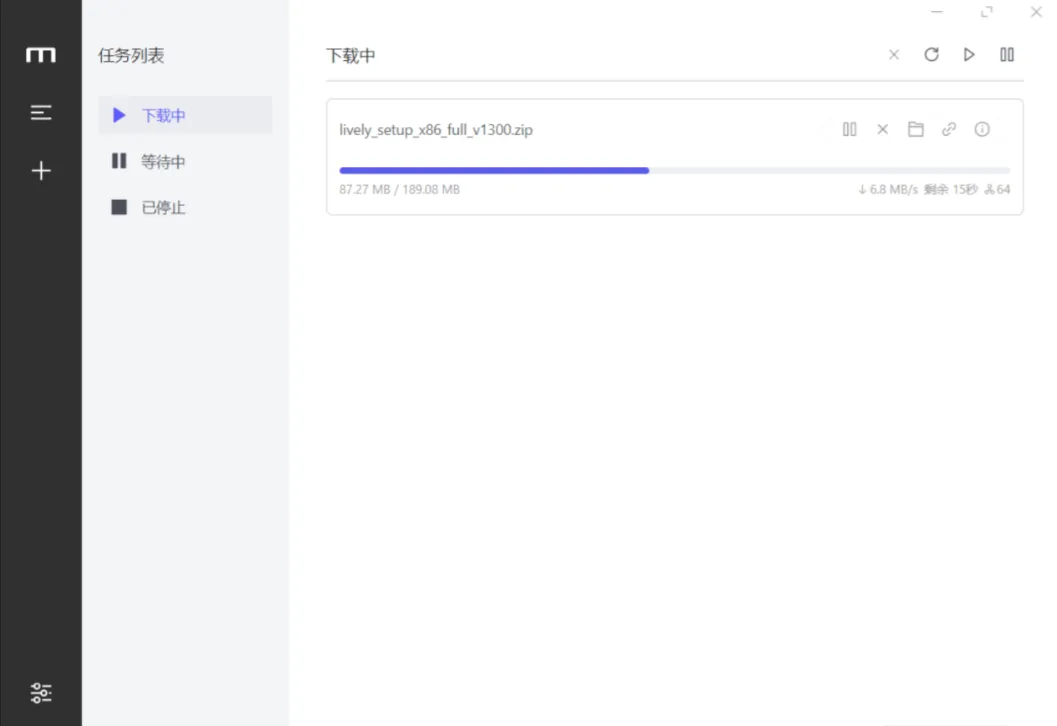
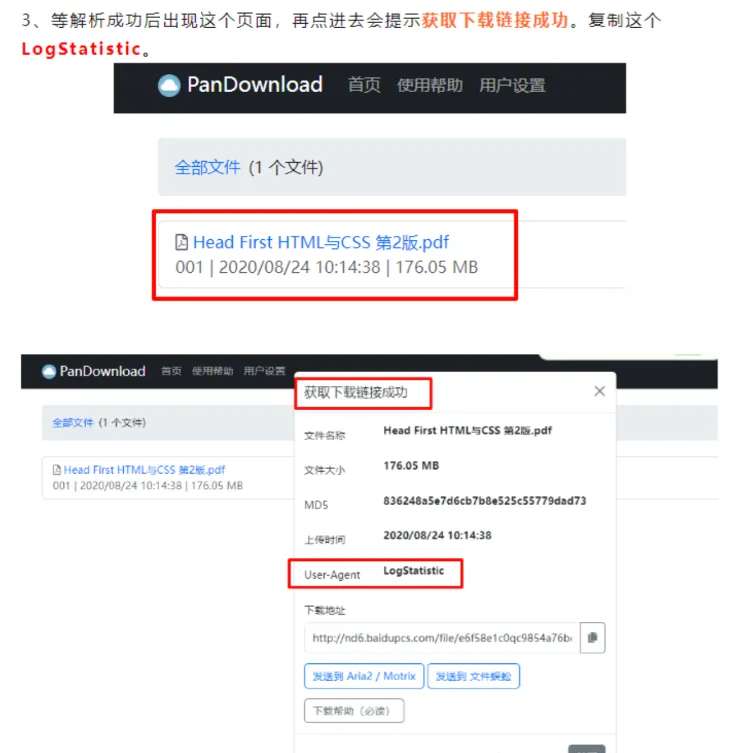
百度网盘最新不限速,永久可用!
一键解析加速5-20M/s❗内置使用教程❗ 【资源名称】:Motrix 【资源版本】:1.8.19 【资源大小】:200M 【测试机型】:win11 【资源介绍】: 资源获取在文末 百度网盘,作为备受欢迎的云存储软件,以其强大的功能和便捷性,成为用户间文件共...
446阅读
0评论
2024/3/29
实用工具
TIKTOK 国际版 最新免拔卡 教程(安卓+苹果)
应大家的要求,很多粉丝反馈明明自己下载了tiktok为啥进去之后还是黑屏,无法使用,那是因为tiktok会检测手机的环境,不会使用的大家可以加入下方交流群来讨论,后期还会更新~ 软件名称:tiktok 支持设备:安卓/鸿蒙/IOS 一、使用教程 前期准备: 1...
522阅读
0评论
2024/3/29
技术教程
Telegram 完美解决接收不了验证码和其他问题~
之前出了一期 Telegram 的软件分享,虽然只发了一点点的教程,因为我在注册的时候挺轻松的,所以就没有发太详细的教程,但是收到大家的反馈都在验证码获取出现了许多问题。今天就为大家做一期完整的教程,和解决可能会出现的各种问题。 在一切开始之前需要做的准备:...
634阅读
0评论
2024/2/21
福利分享
某博下班提神晚餐
点击围观
638阅读
0评论
2024/2/21
福利分享
某博内搭小背心
点击围观
580阅读
0评论
2024/2/19
实用工具
今日水印相机破解版改时间改位置 打卡时间和地点,随意修改
今日水印相机破解版改时间改位置版是由北京小嘿科技有限责任公司推出的一款手机拍照软件。有不少工作因为工作内容的限制都无法每天固定地点打卡,但是这并不意味着就不需要打卡,毕竟考勤极其重要。这种时刻就可以使用今日水印相机破解版改时间改位置版来拍照打卡!
1377阅读
0评论
2024/2/19
赚钱项目
靠卖chatgp账号,4.0代充,日入1000+,精准引流,暴力变现
市面上最强AI,chatgpt目前上市已有1多年多,但苦于国内限制很多想使用的人却不会操作!所谓有需要就有市场,本节课会手把手教大家从注册到充值,和如何引流客户进行变现!全程干货,小白也可当天上手!
517阅读
0评论
«
1
...
12
13
14
15
16
17
18
...
110
»