导航
技术教程
实用工具
值得一看
福利分享
心灵鸡汤
赚钱项目
搜索
赚钱项目
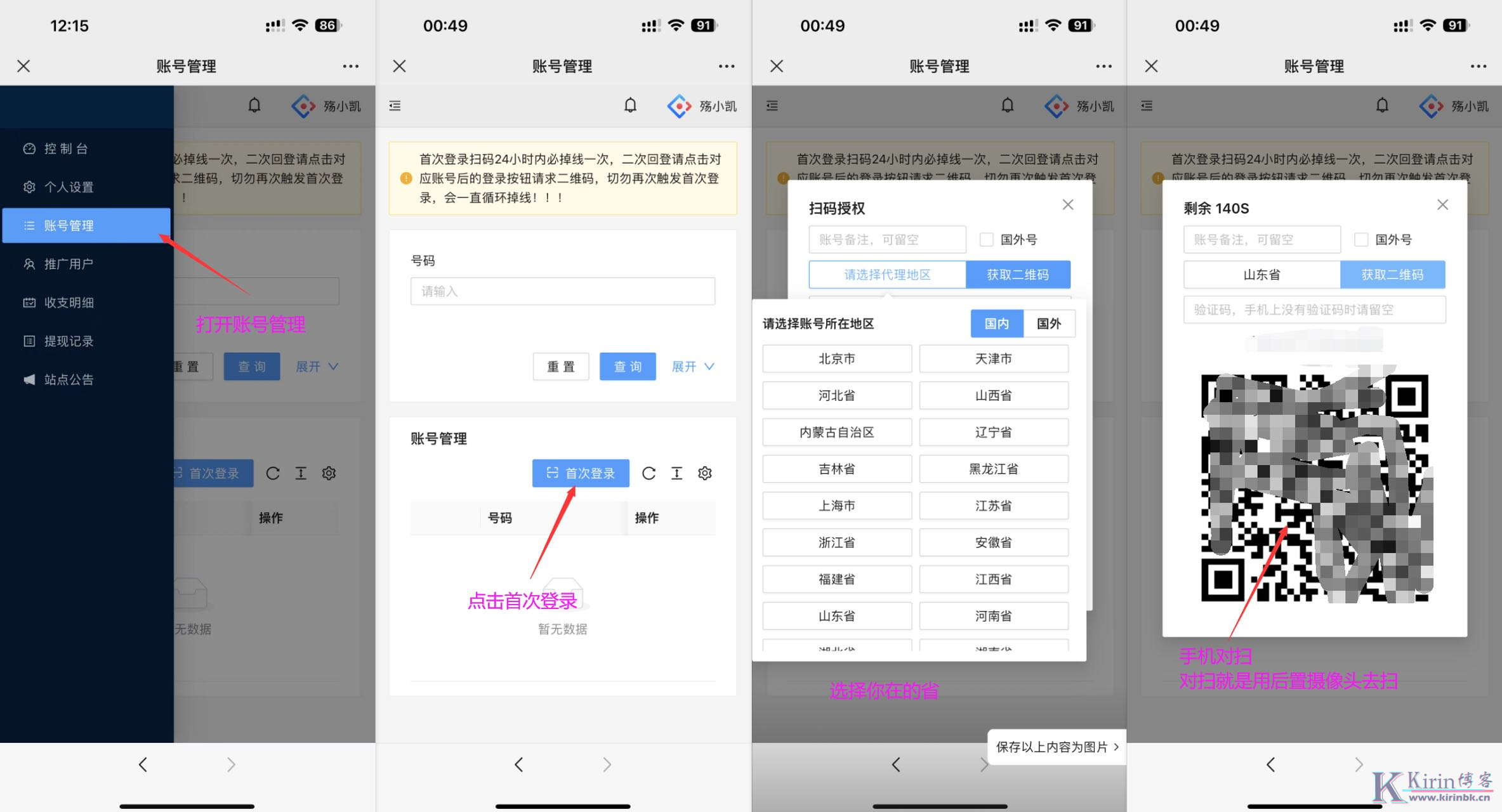
172号卡分销系统推荐人手机号
推荐人手机号
2024/7/25
1500阅读
赚钱项目
新手第一课,教你如何推出第一张卡
2024/7/25
1355阅读
赚钱项目
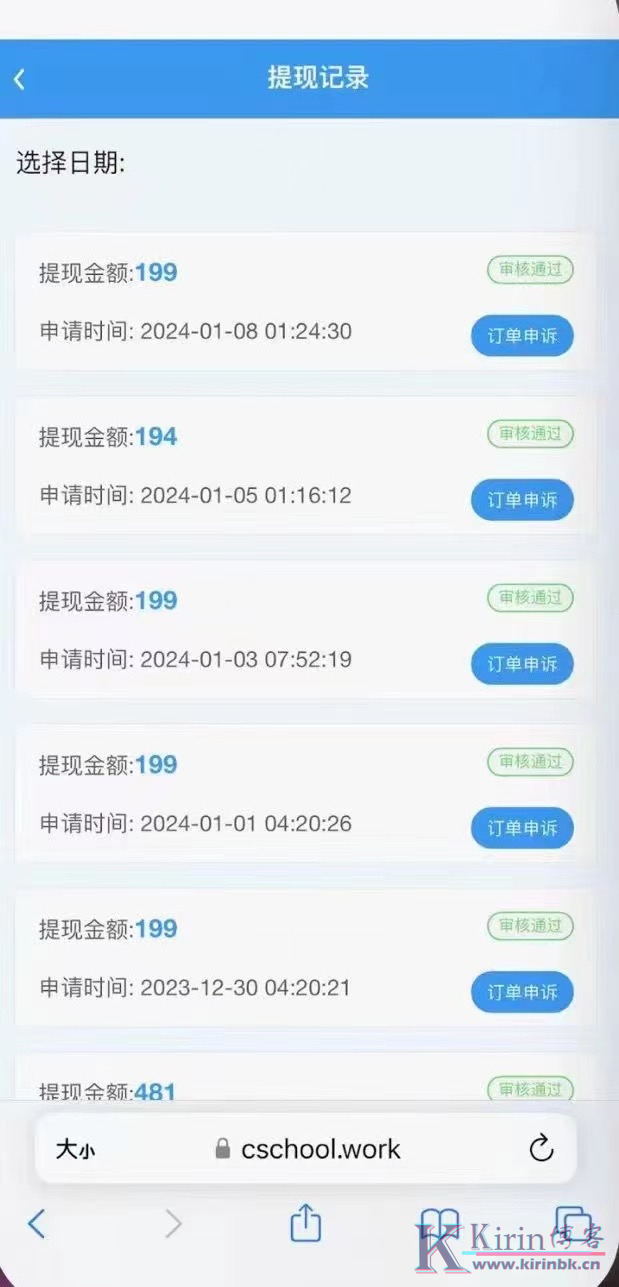
微信视频号托管平台(每天15元现金)
2024/4/10
2084阅读
技术教程
如何绕过网站复制限制?7种实用技巧与合法注意事项
2025/2/26
87阅读
2024/4/10
福利分享
某博JK大赛
点击围观
669阅读
0评论
2024/4/10
福利分享
某博春日贴身内搭大赛
点击围观
580阅读
0评论
2024/4/10
实用工具
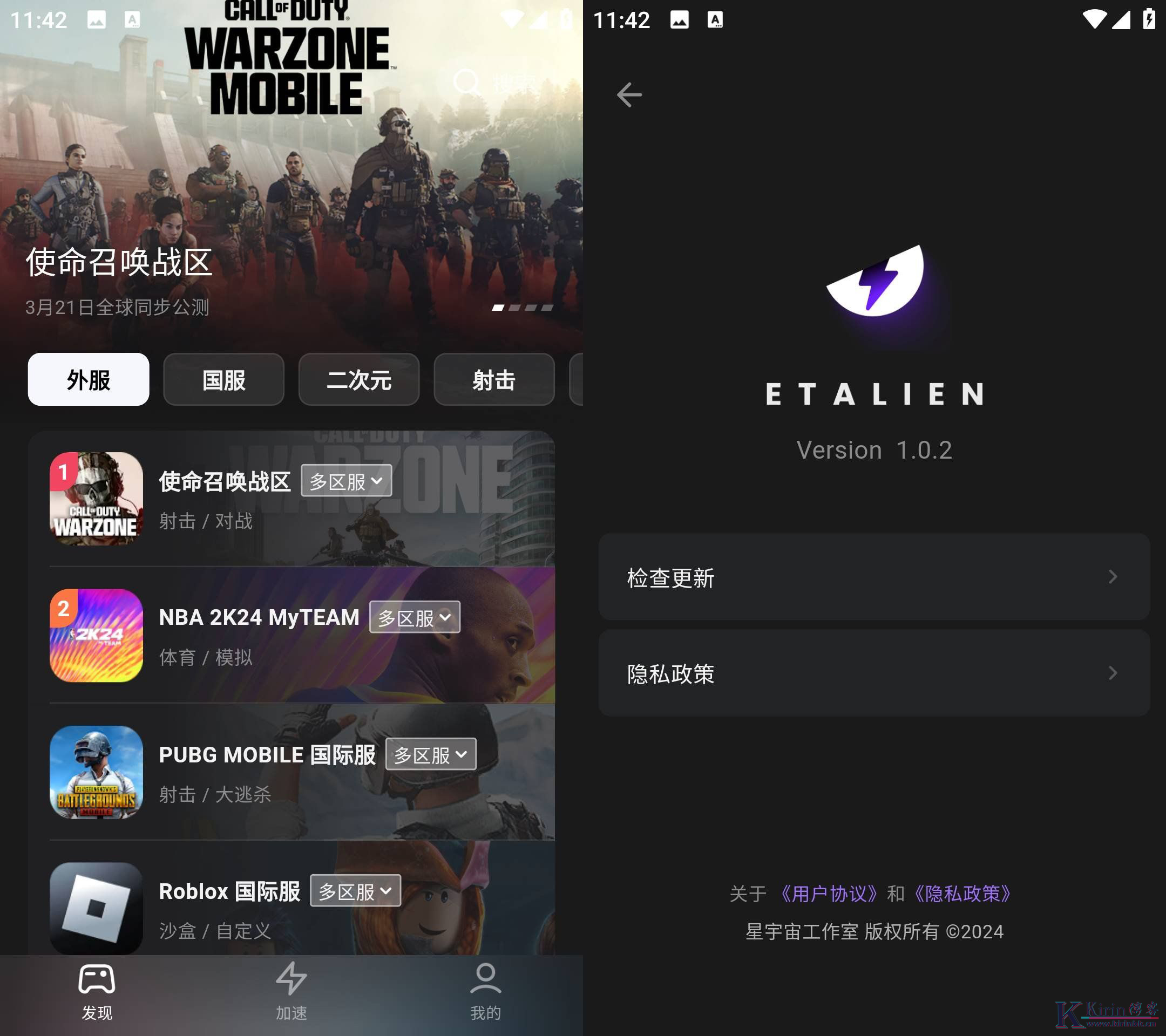
Android 外星人加速器 v1.0.2无广告免费版
软件介绍 外星人加速器是一款可以给游戏加速的软件,也支持一些游戏市场,如steam,xbox等,软件支持国际版游戏加速,如大家玩的pubg,nikke,咒术回战等,都能通过软件加速,需要加速的朋友可以试试这个软件。 软件特色 优化游戏性能,提高帧率和游戏流畅...
505阅读
0评论
2024/4/10
实用工具
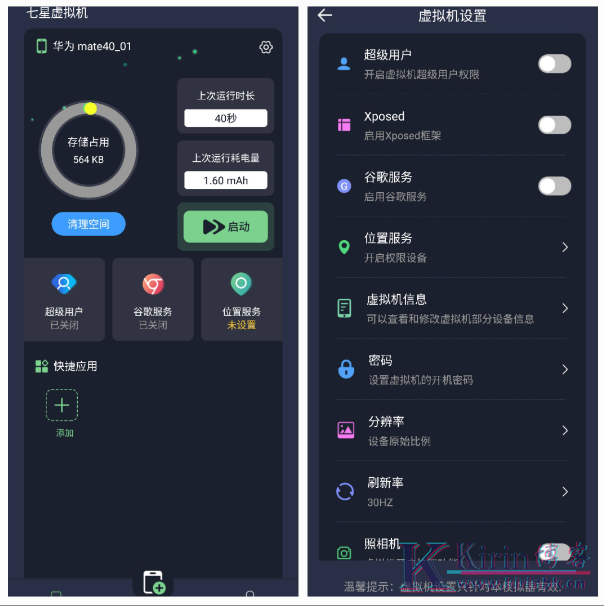
【七星虚拟机】最狠虚拟机,登录就是VIp,地址,机型,随便改
[软件名称]七星虚拟机 [软件大小]162 [软件介绍]七星虚拟机还支持定位模拟功能,让您能够轻松模拟不同的地理位置,满足各种使用需求。同时,它还支持各大厂商的虚拟系统,让您能够根据自己的喜好和需求,选择最适合自己的虚拟系统。【特别说明】解锁会员支持安卓14...
681阅读
1评论
2024/4/10
赚钱项目
微信视频号托管平台(每天15元现金)
微信视频号托管平台 每人都有视频号无需成本 每天稳定15元现金 提现秒到 视频号仅用于点赞关注 一次挂机 长期每月躺赚450元 以下是具体操作流程步骤 注册地址(复制到浏览器打开):https://www.duomini.co/...
2084阅读
0评论
2024/4/10
值得一看
暗网提供工具及服务,骗子利用人工智能工具进行深度伪造
暗网提供工具及服务,骗子利用人工智能工具进行深度伪造 早在2021年,暗网市场就在售卖用于人脸识别的伪造护照、身份证件,而且出现了早期的深度伪造。如今,恶意使用深度伪造技术对企业构成的威胁与日俱增。 网络安全公司卡巴斯基(Kaspersky)警告说,由于人工智...
589阅读
0评论
2024/4/9
值得一看
暗网市场Nemesis在德国主导的国际执法行动中被查封
 根据Dark...
566阅读
0评论
2024/4/9
值得一看
世界上首个暗网市场“丝绸之路”的创始人今天在监狱庆祝40岁生日
今天是3月27日,世界上第一个暗网交易市场丝绸之路的创始人——罗斯·乌布利希(Ross Ulbricht)在监狱里庆祝自己的40岁生日。这位暗网企业家自29岁起在美国被监禁了近11年,一直备受争议。 Ross Ulb...
519阅读
0评论
2024/4/9
值得一看
美国国务院悬赏1000万美元征集暗网勒索团伙ALPHV/BlackCat相关信息
美国国务院由外交安全局管理的正义奖赏计划(Rewards for Justice)周三宣布悬赏1000万美元,寻求更多有关黑猫(ALPHV/BlackCat)勒索软件组织的更多信息。 Help Us Trap This CatALPHV/Black...
503阅读
0评论
2024/4/9
值得一看
AT&T数据泄露:7300万个账户的个人信息和数据被泄露到暗网上
无论您是当前订阅者还是过去拥有过AT&T帐户,您的个人数据都可能成为大规模数据泄露的一部分,根据AT&T给客户的一份说明,该泄露影响多达7300万帐户持有者。 AT&T发生了什么 AT&T周六证实,约7300万当前和老客户...
494阅读
0评论
2024/4/9
值得一看
暗网毒贩在谷歌搜索“最好的性爱药物”后被定罪
根据英国警方的消息,一名通过暗网出售“约会强奸”药物GHB的暗网毒贩在谷歌搜索“最好的性爱药物”后被定罪。 30岁的Wuwuoritsetan Orimolade居住在英国伦敦埃奇韦尔的Deans Way,...
498阅读
0评论
2024/4/9
值得一看
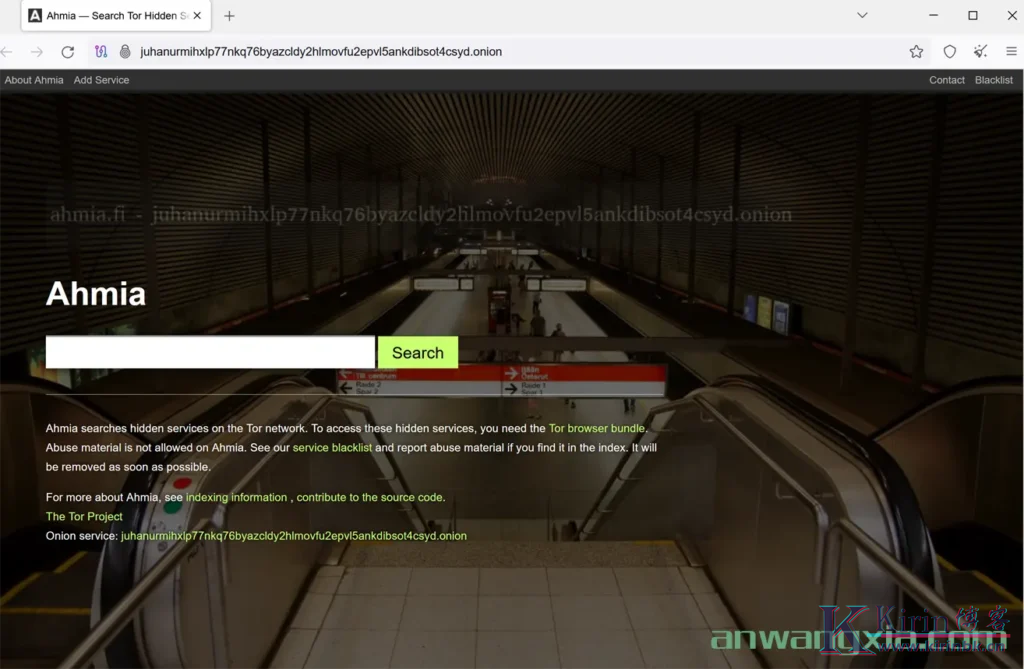
Ahmia依旧是2024年最受关注的暗网搜索引擎
2021年,”Kirin博客“曾经介绍了暗网上最大的搜索引擎之一Ahmia,时隔近三年,Ahmia依旧是最受关注的暗网搜索引擎。本文讨论Ahmia、它的工作原理、功能和优点、安全预防措施以及与其他暗网搜索引擎的比较。 您是否想过互...
460阅读
0评论
2024/4/9
值得一看
到2032年,暗网情报市场将达到约29.218亿美元
介绍 暗网情报市场已成为全球网络安全领域的重要组成部分。2023年,暗网情报市场规模达到5.203亿美元,预计到2032年将大幅增长至29.218亿美元,预测期内复合年增长率预计为21.8%。这种强劲增长是由多种因素推动的,包括在线欺诈活动数量的增加以及...
466阅读
0评论
2024/4/8
技术教程
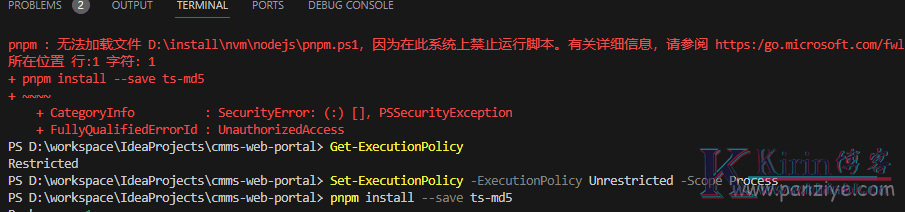
vscode执行pnpm : 无法加载文件 pnpm.ps1,因为在此系统上禁止运行脚本解决办法
文章目录 问题原因 解决办法 在vscode上运行pnpm install时提示:pnpm : 无法加载文件 D:\install\nvm\nodejs\pnpm.ps1,因为在此系统上禁止运行脚本,这个问题该如何解决呢? 问题原因 ...
726阅读
0评论
2024/4/8
赚钱项目
2024年灵异故事,视频号创作者分成,小白轻松上手,轻松日入1000+
项目介绍 老窦今天给大家带来的项目是《2024年灵异故事,视频号创作者分成,小白轻松上手,轻松日入1000+》;视频号创作者分成,我们深耕8个月,同步更新了多种玩法,今天带来全新赛道--灵异故事;灵异故事是现在很多人都喜欢的视频类目,因为人总是有一种好奇心、...
513阅读
0评论
2024/4/8
赚钱项目
AI电影动漫100%过原创,日入2000+,视频号分成计划最新项目,小白首选!
项目介绍 今天给大家带来的项目是视频号创作者分成计划2024最新破收益技术,AI电影动漫100%原创,目前是蓝海,作品全部是原创。情感类电影情节通过软件变成AI动漫视频,条条爆款,条条原创!
538阅读
0评论
2024/4/8
赚钱项目
全网首发!不一样的小说推文玩法,原创漫画一键制作,小白轻松上手,单日可入3000+
项目介绍 小说推文的玩法很早就有了,以前的玩法要么直接把文字放到图片上,然后做成视频,要么放个解压视频,再加上配音,这些方式观众代入感不强,所以收益也不会很高。今天我们要介绍的是一种全新的小说推文玩法,通过AI把小说的内容变成漫画,再通过剪映制作成视频,加上...
479阅读
0评论
2024/4/8
赚钱项目
暴力引流玩法,全网引流合集,以及咸鱼引流玩法
课程目录 暴力引流玩法 咸鱼引流 (注意全为免费,不收任何费用)
470阅读
0评论
2024/4/8
赚钱项目
淘宝超高价项目,1单赚1000多,店铺矩阵操作
项目介绍 项目介绍:淘宝超高价0销量也能出单 定位:凭什么卖1000多有人买 选品:1000多能出单又减小退货 刷单:三个阶段非搜补单操作 低预算付费推广:每天30元引流100个 矩阵放大:模式跑通后复制多店
475阅读
0评论
2024/4/8
赚钱项目
AI微头条动漫吸钱玩法,轻松日入300+
项目介绍 Hello,大家好!我是天哥,今天给大家介绍的项目是AI微头条动漫吸钱玩法,轻松日入300+
456阅读
0评论
«
1
...
9
10
11
12
13
14
15
...
110
»