导航
技术教程
实用工具
值得一看
福利分享
心灵鸡汤
赚钱项目
搜索
赚钱项目
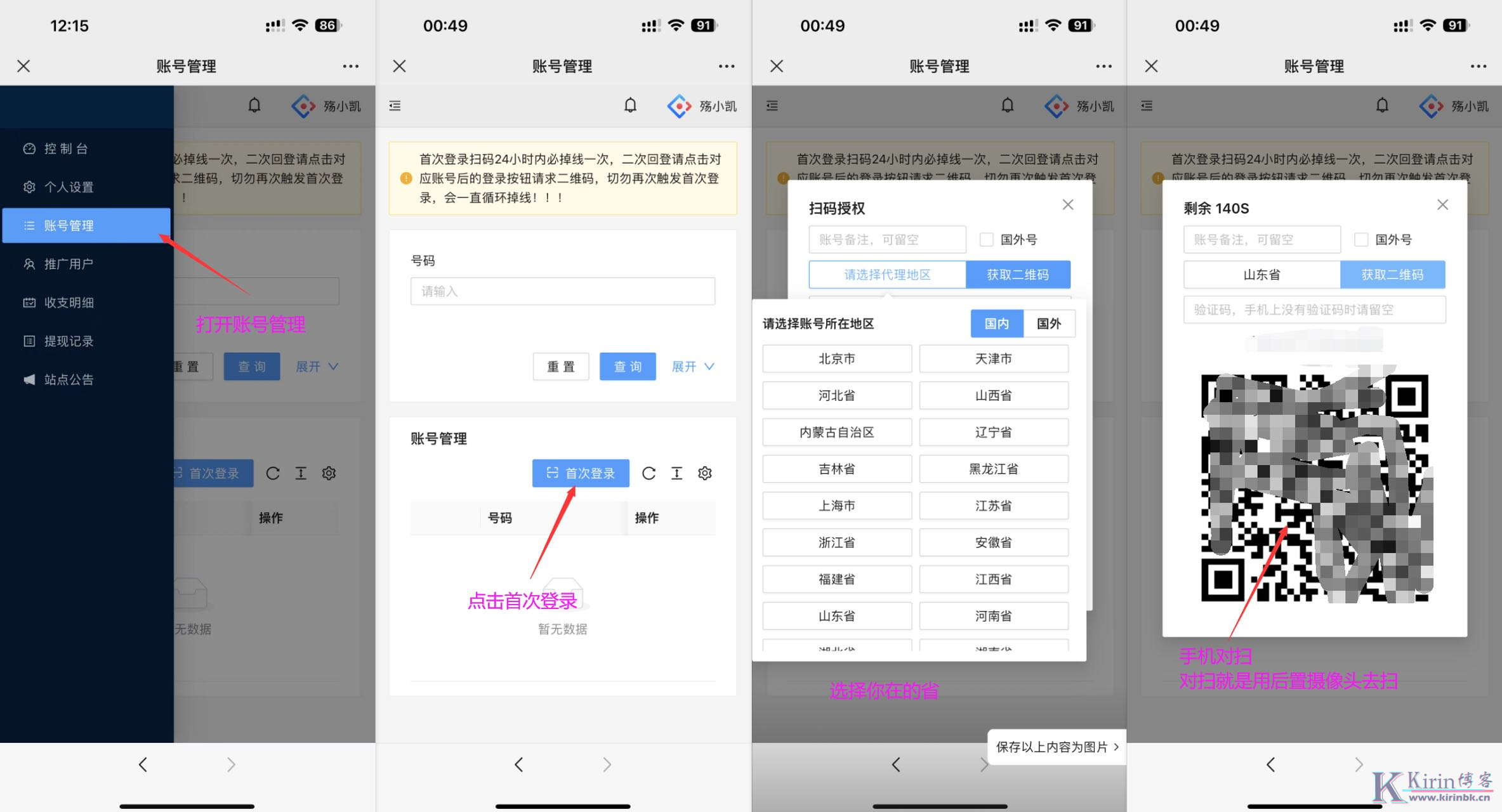
172号卡分销系统推荐人手机号
推荐人手机号
2024/7/25
1500阅读
赚钱项目
新手第一课,教你如何推出第一张卡
2024/7/25
1355阅读
赚钱项目
微信视频号托管平台(每天15元现金)
2024/4/10
2084阅读
技术教程
如何绕过网站复制限制?7种实用技巧与合法注意事项
2025/2/26
87阅读
2024/2/19
福利分享
某博少女感大赛
点击围观
541阅读
0评论
2024/2/19
福利分享
某博漏点大赛
点击围观
484阅读
0评论
2024/2/18
福利分享
某博春节旗袍大赛
点击围观
474阅读
0评论
2024/2/18
福利分享
某博侧身拍大赛
点击围观
446阅读
0评论
2024/2/17
福利分享
某博少女感大赛
点击围观
468阅读
0评论
2024/2/17
福利分享
某博假期隐藏相册
点击围观
470阅读
0评论
2024/2/17
技术教程
24年强开花呗教程
吧闲的无聊逛某鱼 发现竟然有卖支付B强开花呗的教程 (因为自己也没开所以下款看看) 但看完教程觉着太麻烦 想着就这点破教程还卖个五六块 就来这里给大家分享一下 第一步: 支付宝开通网商银行存200金余利宝 等收到3天活期利...
814阅读
0评论
2024/2/17
赚钱项目
免费薅风鸟类似天眼查一年会员
亲测可以使用,不像企查查天眼查要开超级vip的套路业务。有需要查企业老板电话,做企业背景调查的。大家可以去注册。目前平台有活动,注册就送一年会员 注册链接:https://m.riskbird.com/h5/pages/user/vip/share?shar...
546阅读
0评论
2024/2/17
实用工具
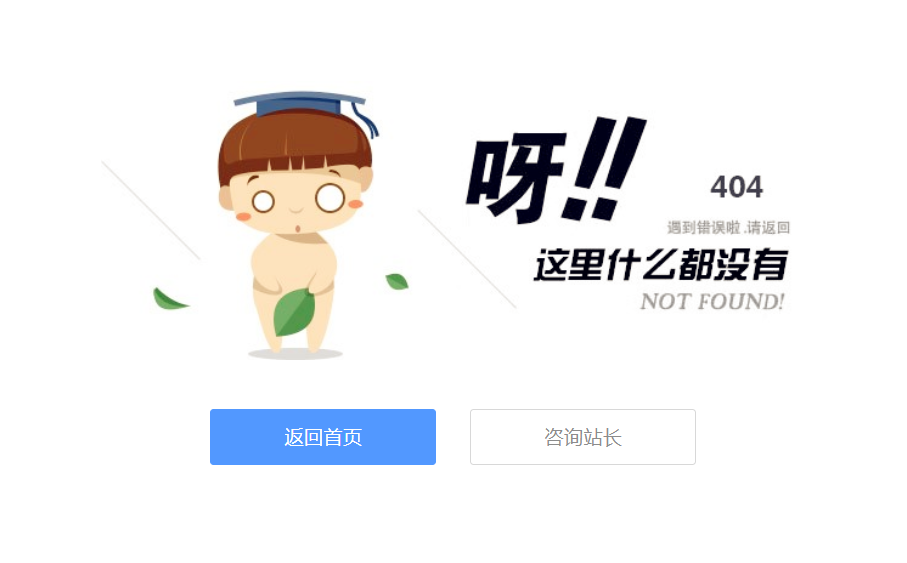
可爱卡通小人404页面源码
对于对404页面没有其他特殊需求的朋友来说,有这样一个页面足矣,很多站长都在用。
421阅读
0评论
2024/2/17
实用工具
动态雨滴玻璃效果实现个人主页html源码
主页动态雨滴玻璃掉落效果重构:全新CSS布局与canvas下雨背景绘制。用户可自由更换背景图片,为网页带来丰富多彩的视觉体验。
478阅读
1评论
2024/2/16
值得一看
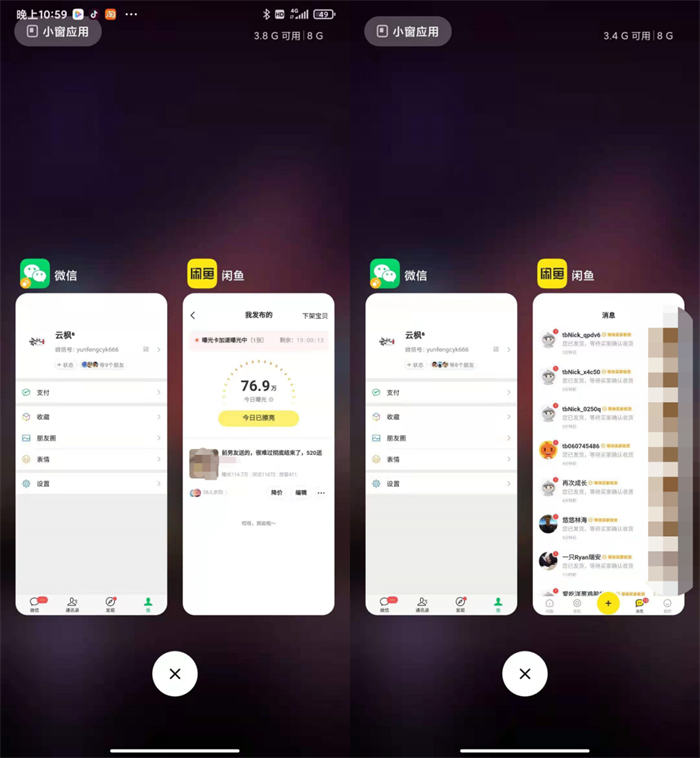
五天时间 闲鱼曝光76W,当天卖出86单
很多朋友问我,说看我近期动态,最近怎么这么闲,每天到处旅游玩。统一回复下就是:生活不止眼前的苟且,还有诗和远方。小装一下哈哈哈哈。 这几年搞了不少项目,每次项目遇到瓶颈,很烦躁的时候其实都想着当个甩手掌柜,去西藏洗礼,去洱海吹风,去内蒙古骑马。但现实是没办法...
489阅读
0评论
2024/2/16
实用工具
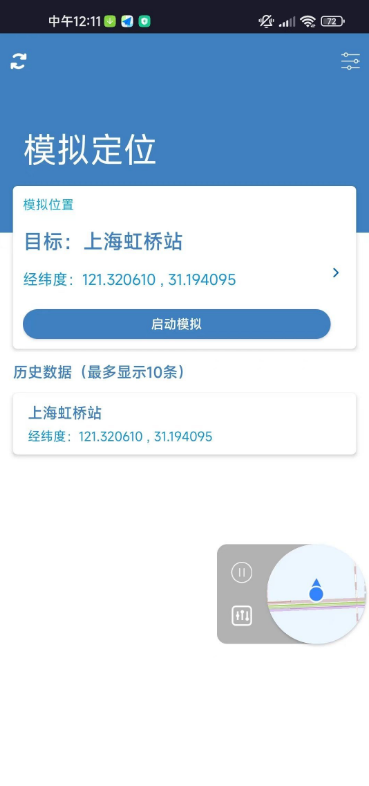
虚拟定位点点守护V2.0.3 亲测能打卡能签到
测试来下打卡签到都正常 使用方法: 1.先打开考勤软件 2.打开点点守护调整位置 3.返回打卡软件即可
492阅读
0评论
2024/2/16
实用工具
黑色响应式全屏滚动主页源码
html5黑色大气的个人博客全屏滚动个人主页源码下载,右键记事本即可修改。HTML+JS+CSS
518阅读
0评论
2024/2/16
实用工具
全网首发-wechat协议接口分享(价值5w
全网首发-wechat协议接口分享(价值5w) 几乎涵盖所有功能,仅供学习交流使用!
455阅读
0评论
2024/2/16
福利分享
某博假期相册
点击围观
499阅读
0评论
2024/2/16
福利分享
某博男友视角大赛
点击围观
470阅读
0评论
2024/2/16
值得一看
勒索软件和暗网加密市场活动在2024年呈上升趋势
2023年,加密勒索软件的范围、攻击频率和数量均有所增加。根据Chainalysis的[《2024年加密犯罪报告》,这些攻击造成了11亿美元的加密货币损失。 根据该报告,现在的制胜策略之一是“大型狩猎游戏”,网络犯罪分子...
481阅读
0评论
2024/2/16
值得一看
从追踪暗网上网络犯罪的演变中汲取的经验教训
互联网的一个隐藏部分被称为“暗网”,它不可见,也无法使用标准搜索引擎进行搜索。与互联网非常相似,暗网也是一个由商业网站和市场组成的生态系统。不同的是,这些网站通常销售非法、禁止或具有攻击性的产品和服务。 暗网起源 ---- 暗网的起源...
444阅读
0评论
2024/2/15
福利分享
某博床上自拍
点击围观
653阅读
0评论
2024/2/15
福利分享
某博紧身牛仔裤yyds
点击围观
406阅读
0评论
«
1
...
13
14
15
16
17
18
19
...
110
»