
world转Json
我有两个docx文档分别存放Qustion和Solution,我想将其转换为
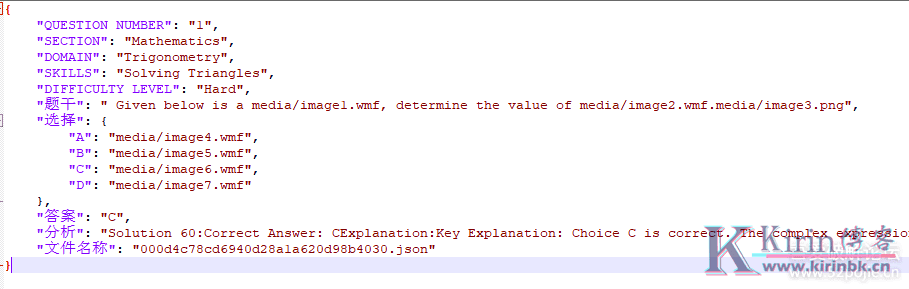
这样的json格式
Question文件:
Solution文件:

我在网上找了一会儿没有找到相关的软件资料,但想到了由于docx本质是xml和资源文件形成的文档,所以想着自己开发实现一下。
由于又有图片又有文字,所以这里面最主要需要实现的就是如何将文本和图片路径进行拼接,若只有图片文件倒也好办,可以直接通过查找对应段落下的'r:embed'即可找到所有图片,但文档中还有wmf格式的图片,试用'r:embed'无法查找到,我找了半天也没找到有什么办法可以直接提取wmf文件,最后只有返璞归真。
我们到document.xml.rels中找到wmf文件对应资源的id,(其中document.xml.rels在./directory_name/word/_rels下)
以id为rId406d的为例,我们到document.xml中搜索该id

可以发现他存在于
r:id中,那么我们就可以通过元素查找找到对应id再去_rels中找到对应Target路径。
具体实现:
import os
from zipfile import ZipFile
from xml.etree import ElementTree as ET
def get_rel(rid):
# rel_tree = ET.parse('./ACT_Maths_Mock Paper1_Questions/word/_rels/document.xml.rels')
rel_tree = ET.parse('./ACT_Maths_Mock Paper1_Solutions - 副本/word/_rels/document.xml.rels')
rel_root = rel_tree.getroot()
namespace = {'ns': 'http://schemas.openxmlformats.org/package/2006/relationships'}
relationship = rel_root.find(f".//ns:Relationship[@Id='{rid}']", namespaces=namespace)
# 如果找到对应的 Relationship 元素,则获取 Target 属性的值
if relationship is not None:
target_value = relationship.attrib.get('Target')
return target_value
def read_text_and_media_from_xml(output_folder):
# 解压文件
# 解析文本和媒体资源
xml_path = os.path.join(output_folder, 'word/document.xml')
media_dir = os.path.join(output_folder, 'word/media/')
tree = ET.parse(xml_path)
root = tree.getroot()
content = []
# 处理文本内容
#遍历p下面的元素
for paragraph in root.findall('.//{http://schemas.openxmlformats.org/wordprocessingml/2006/main}p'):
texts = []
for r_element in paragraph.findall('.//{http://schemas.openxmlformats.org/wordprocessingml/2006/main}r'):
for elem in r_element.iter():
eles = elem.findall('.//{http://schemas.openxmlformats.org/wordprocessingml/2006/main}t')
for ele in eles:
texts.append(ele.text)
for key, value in elem.attrib.items():
if key.endswith('}embed'):
embed_id = elem.attrib.get(
'{http://schemas.openxmlformats.org/officeDocument/2006/relationships}embed')
target_value = get_rel(embed_id)
texts.append(target_value)
if key.endswith('}id'):
target_value = get_rel(value)
#其中还包含bin文件,我们要过滤wmf文件
if "wmf" in target_value:
texts.append(target_value)
text_content = ''.join(texts)
content.append(text_content)
return '\n\n'.join(content)
extracted_folder = './world' #转为.zip再解压后的文件夹路径
# 读取文本内容和媒体资源的示例
document_content = read_text_and_media_from_xml(extracted_folder)
print("文档内容及媒体资源信息:")
print(document_content)
with open('./ts2.txt','w',encoding='utf-8') as f:
f.write(document_content)
根据以上流程对document.xml进行解析,理论上我们可以获得docx中的任意数据并任意操作任意组合。发文记录一下思路想法。
-
image-20240723151633991.png (29.97 KB, 下载次数: 1)


