导航
技术教程
实用工具
值得一看
福利分享
心灵鸡汤
赚钱项目
搜索
首页
标签
master
2023/11/7
值得一看
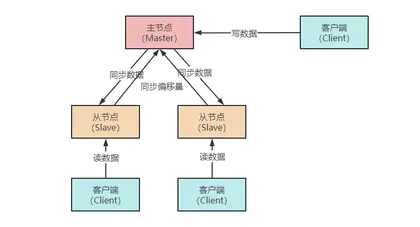
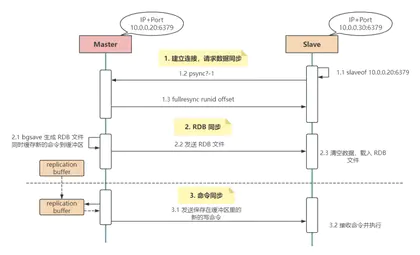
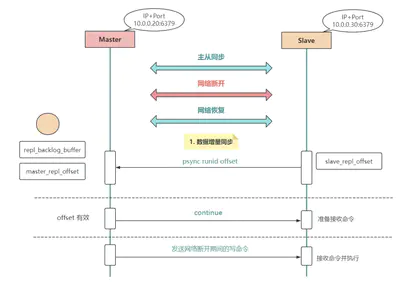
Redis主从复制原理详解
众所周知,一个数据库系统想要实现高可用,主要从以下两个方面来考虑: 保证数据安全不丢失 系统可以正常提供服务 而 Redis 作为一个提供高效缓存服务的数据库,也不例外。 上期我们提到的 Redis 持久化策略,其实就是为了减少服务宕机后数据丢失,以及快...
471阅读
0评论
没有更多了~