导航
技术教程
实用工具
值得一看
福利分享
心灵鸡汤
赚钱项目
搜索
首页
标签
架构
2023/11/2
值得一看
什么是数据复制,有哪些架构
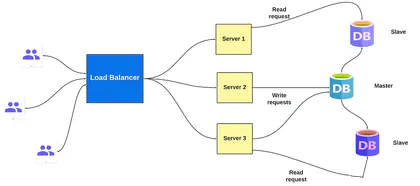
数据复制是指将数据复制到一个或多个数据容器以确保可用性的过程。 复制的数据通常存储在不同的数据库实例中,即使一个实例发生故障,我们也可以从其他实例获取数据。 一种流行数据复制的实现架构是主从架构。 主从架构 为了理解这个架构,我们举一个例子。 我们有四个客...
500阅读
0评论
没有更多了~