导航
技术教程
实用工具
值得一看
福利分享
心灵鸡汤
赚钱项目
搜索
首页
Bee
列表
2023/8/19
赚钱项目
情人节风口 卖“杏商”课合集(海王秘籍) 一单99 一周能卖1000单 暴...
今天给大家带来的项目是《一单利润99 一周能出1000单,卖杏商课程合集(海王秘籍),暴力掘金》“情人节“,即将来临,关于“性商”方面的课程,肯定会大卖!这类课程的需求很大,我已经帮大家整理好课程合集给大家,...
411阅读
0评论
2023/8/19
实用工具
免授权视频解析计费系统v1.8.2源码分享
免授权,原作者卖88,带七套模板之前有分享过 1.7.1 的影视计费系统,那个版本很久了之前也一直没有更新,拿到源码之后进行优化,因历史版本的加载和原版的加载速度真的是慢的感人,因此从零开始进行去授权,所有源码均本地化,避免因为外链导致的程序不能正常使用,就...
431阅读
0评论
2023/8/19
赚钱项目
轻松月人万的蓝海高需求 证件照发型项目全程实操教学
冷门高需求 现在市场上没有同行 超级详细教程 全程实操来了 陪跑项目价值几千
395阅读
0评论
2023/8/19
赚钱项目
男粉3.0,无脑操作,日入1000+全自动变现(掘金系统+教程+素材+软件)
哈喽,大家好,欢迎来到男粉项目3.0,无脑操作日入1000+,全自动变现,全网独一份。 那么关注我们的学员呢,应该知道我们这个南粉项目是从四月份开始做的,四月份呢,我们做出了粉项目1.0,那个时候是账号最好做的时候, 还记得很多学员一晚上赚个五六百,轻轻松松...
428阅读
0评论
2023/8/18
值得一看
网站被恶意刷流量关键词怎么办?
网站最近人大量的刷恶意关键词,恶意刷流量了,虽然对网站运营没有啥大影响,最多就是影响点搜索引擎的收录,对我这种小站来说没啥大的影响,但是就是有点恶心人。 正常来说,一个关键词搜索量固定,而你的流量统计显示有更多点击,有可能被刷点击,或者看到一些关键词前后带数...
452阅读
0评论
2023/8/18
值得一看
潜伏二十多年漏洞曝光,几乎所有VPN都中招!
近日,纽约大学和鲁汶大学的研究人员发现大多数VPN产品中都存在长达二十多年的多个漏洞,攻击者可利用这些漏洞读取用户流量、窃取用户信息,甚至攻击用户设备。 “我们的攻击所需的计算资源并不昂贵,这意味着任何具有适当网络访问权限的人都可以实施这些攻...
486阅读
0评论
2023/8/18
值得一看
剖析针对工业组织的常见攻击TTP
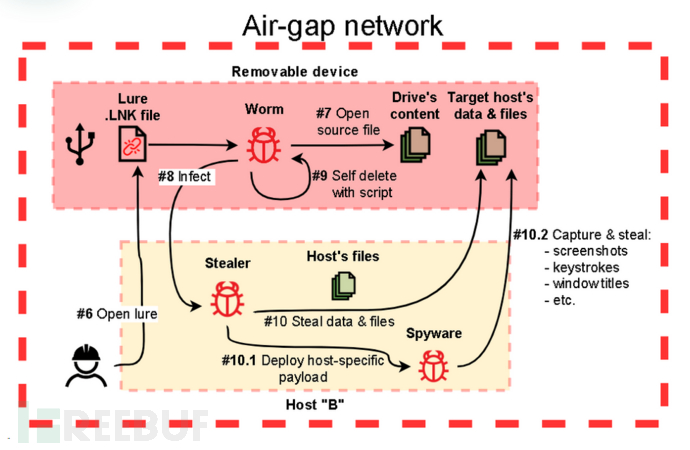
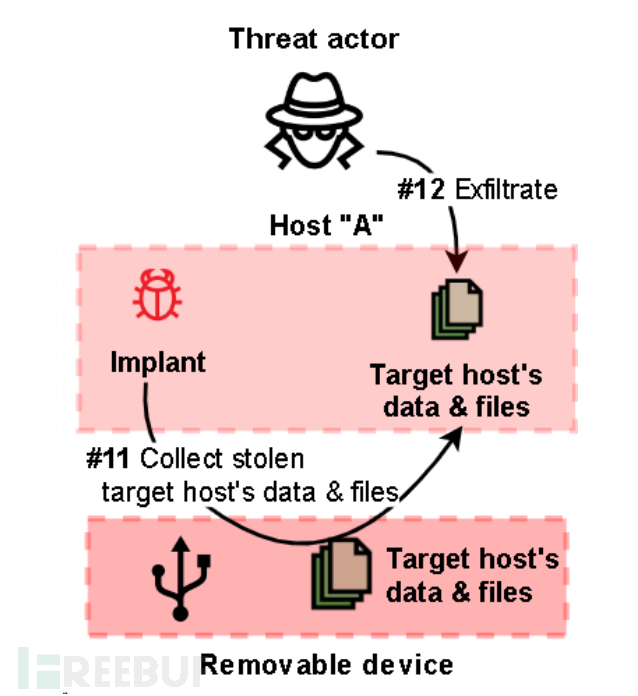
2022年,卡巴斯基研究人员调查了一系列针对东欧工业组织的攻击活动。在这些活动中,攻击者的目标是建立一个永久的数据泄露渠道,包括存储在气隙(air-gapped)系统中的数据。 基于这些攻击活动与之前研究过的攻击活动(如ExCone、DexCone)存在诸多...
458阅读
0评论
2023/8/18
技术教程
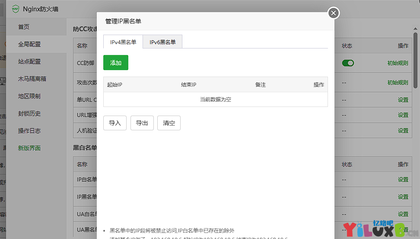
宝塔面板Nginx防火墙ip白名单无效怎么办?
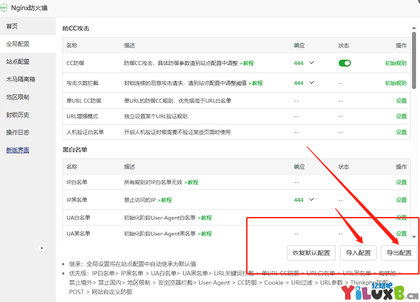
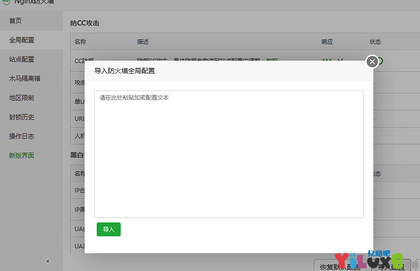
对宝塔的Nginx防火墙进行卸载重装或者点过修复后,重新导入数据发现有问题,通过宝塔的备份功能导入的数据ip黑白名单会失效。 今下午突然发现网站对CDN节点ip进行了错误拦截导致无法访问,很莫名其妙,我防火墙明明添加了ip白名单竟然还会拦截。 第一时间怀疑是F...
603阅读
0评论
2023/8/18
值得一看
暗网勒索组织猖獗,LockBit发布8个新的受害者,Clop利用MOVEit窃取数百万美国人的健康数据
“Kirin博客”监测发现,近期,据称有俄罗斯政府背景的勒索软件团伙十分高产,继上周新增15名受害者后,LockBit勒索软件团伙又在其暗网数据泄露门户中增加了8名新的受害者,而Clop勒索软件团伙则利用广泛使用的MOV...
473阅读
0评论
2023/8/18
值得一看
深入研究暗网监控、数字风险防护服务
近年来,网络攻击的频率显着上升。攻击者越来越多地不仅出于经济利益,而且出于政治动机。各类公司正成为各种形式网络犯罪的受害者,例如网络钓鱼攻击和数据泄露。 为了防范这些威胁,专家建议使用专门的数字风险保护(DRP)服务。这些服务不仅有助于识别互联...
421阅读
0评论
2023/8/18
实用工具
最简单粗暴的抖音起号方法
1 、找到一个自己感兴趣的热点。从微博热搜或抖音热榜里找。 2 、围绕手左点,深挖内容,做二三十个选题。可以在微博、B 站、知乎搜索。 3 、陆续把选题发到自己的抖音号上。几个号一起发。用不同模板和音乐。只要播放量能过 100 就继续发。 4 、哪条抖音成了爆...
474阅读
0评论
2023/8/18
值得一看
为什么说 PHP 是世界上最好的编程语言
众所周知,PHP 是世界上最好的编程语言。 当然大家都知道这只是调侃 PHP 的一个梗,这个梗来自 PHP 官方文档里的一句描述:PHP is the best language for webbing。意思是 PHP 是构建网站最好的语言。这句话,最早出现在...
404阅读
0评论
2023/8/18
值得一看
SEO优化技巧 交换友情链接必须知道的几点知识
作为一名SEO从业者,我们必须知道友情链接是网站优化中不可或缺的一部分。通过与高权重网站的交换友情链接,可实现权重传递,从而帮助自己的网站提升权重,提升关键词排名以及流量,从而带来潜在客户。然而,友情链接的价值也取决于其质量,因此在选择友情链接时要谨慎,选择优...
437阅读
0评论
2023/8/18
实用工具
彩虹云商城模板免费分享,带看板娘
index.php 文件上传到 目录 /template 记得新建一个文件夹 看板娘 Kbn.zip 解压到 目录 /assets 字体eziyuanxiaoqingsenjianfanzhunhei.ttf 文件放到 目录/assets
455阅读
0评论
2023/8/18
实用工具
新云BBR原版/魔改/plus/锐速多合一脚本linux加速脚本/硬盘挂载/cc防御/宝塔/测速/服务器vps测试脚本/一键更换yum脚本2.0.0
服务器vps测试脚本大全{服务器测试专用} 一键更换yum脚本 一键优化shh卡顿 一键更换软件源 各种linux加速 BBR原版 bbrplus 魔改plus 锐速 脚本linux加速脚本 一键硬盘挂载 一键cc防御 一键安装宝塔 一...
483阅读
0评论
2023/8/18
心灵鸡汤
红灯停绿灯行黄灯亮了等一等儿歌
“红灯停,绿灯行,黄灯亮了等一等”是儿歌《红绿灯》的歌词,具体歌词如下:马路上车辆多交通规则要记牢红灯停绿灯行黄灯亮了等一等过马路左右看斑马线上最安全不乱跑不打闹交通规则要记牢马路上车辆多交通规则要记牢红灯停绿灯行黄灯亮了等一等过马路左右看斑马线上最安全不乱跑...
582阅读
0评论
2023/8/18
心灵鸡汤
搜索黄家驹的歌[不再犹豫、喜欢你、不可一世、大地]的歌词
不再犹豫作词:小美 作曲:黄家驹演唱:Beyond无聊望见了犹豫达到理想不太易即使有信心斗志却抑止谁人定我去或留定我心中的宇宙只想靠两手向理想挥手问句天几高心中志比天更高自信打不死的心态活到老OH… 我有我心底故事亲手写上每段得失乐与悲与梦儿OH… 纵有创伤不...
521阅读
0评论
2023/8/18
心灵鸡汤
想起我和你牵手的画面是什么歌 有完整的歌词吗
1、想起我和你牵手的画面是《想起》里面的歌词。2、完整歌词:回到相遇的地点才知我对你不了解以为爱得深就不怕伤悲偏偏爱让心成雪我独自走在寂寞的长街回忆一幕幕重演我告诉自己勇敢去面对就算心碎也完美想起我和你牵手的画面泪水化成雨下满天如果我和你还能再见面就让情依旧梦...
450阅读
0评论
2023/8/18
心灵鸡汤
吃火锅的文案怎么写?
吃火锅的文案如下:1、冬天最适合和你一起吃火锅。2、来自金亭的新鲜健康美味。3、忠诚的船长,让文化与美味同步。4、让我们红尘作伴,吃得潇潇洒洒。5、封锁一切迩旳消息,却封锁不了这颗心。6、我有烧烤和啤酒,就问你跟不跟我走。7、天气冷吃火锅,暖暖身子,是个好主意...
504阅读
0评论
2023/8/18
心灵鸡汤
我跨过千山万水只想再见你一面是那首歌歌词
胡彦斌 《江湖再见》歌词作词:宁财神作曲:胡彦斌演唱:胡彦斌灯火阑珊墨迹还未干烈酒一盏把思念点燃借你的剑不知何时还欠你的情不知该怎么还前世若真的有缘又何必让你为难此生若注定无缘又何苦让我心酸我走过千山万水只想再见你一面栀子花开的时节让我们江湖再见飞雪连天笑唱菩...
467阅读
0评论
«
1
...
40
41
42
43
44
45
46
...
110
»